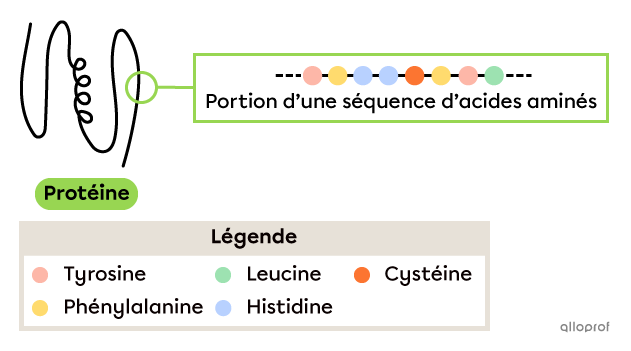
On retrouve plus de 100 000 protéines différentes dans le corps humain. Chacune d’entre elles doit être fabriquée par l’organisme afin de remplir un rôle bien spécifique.
Les protéines
La synthèse des protéines
Les protéines sont des macromolécules (grosses molécules) formées d’une chaine plus ou moins longue d’acides aminés.
Il existe 20 types d’acides aminés standards. Ces acides aminés sont des composés de petite taille qui se lient entre eux pour former une chaine qui peut être courte ou encore très longue. Une fois la protéine formée, les interactions entre les acides aminés forcent la chaine à se replier, ce qui donne une forme caractéristique à chaque protéine.

L’alimentation représente une source de protéines. Le système digestif permet de digérer ces protéines en brisant les liens qui unissent les acides aminés. Ces acides aminés peuvent ensuite être absorbés dans le sang et être distribués aux cellules afin que celles-ci synthétisent de nouvelles protéines.
Les protéines sont des molécules essentielles aux organismes vivants ainsi qu’au fonctionnement des virus. Leurs rôles sont très variés et sont déterminés par leur composition et leur forme tridimensionnelle.
-
Les anticorps sont des protéines dont le rôle est de reconnaitre les corps étrangers afin de déclencher les réactions de défense immunitaire de l’organisme.
-
La lactase est également une protéine. Son rôle est d’agir en tant qu’enzyme en dégradant le lactose, un sucre complexe. La lactase participe donc à la digestion chimique des aliments.
-
L’hémoglobine est une protéine dont le rôle est de fixer et de transporter l’oxygène dans le sang.
-
Le collagène est une protéine qui permet, entre autres, de maintenir la cohésion et la résistance de la peau. Le collagène est également présent dans d’autres tissus du corps.
Pour assurer le bon fonctionnement du corps humain, les cellules doivent effectuer des réactions chimiques, se défendre des attaques de corps étrangers, transporter des particules, etc. Les protéines ont un rôle important à jouer dans toutes ces fonctions. Puisqu’il existe une grande variété de fonctions, le corps doit synthétiser une grande variété de protéines.
La synthèse d’une protéine consiste à lier des particules simples (les acides aminés) afin d’obtenir une chaine complexe appelée protéine.
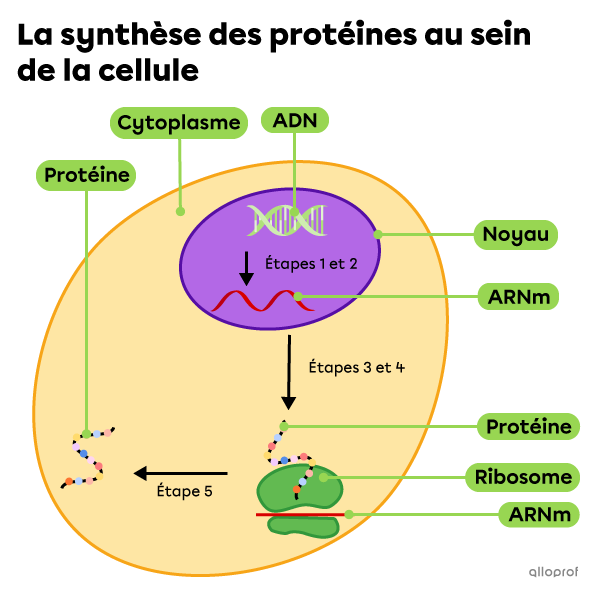
On subdivise la synthèse des protéines en deux étapes : la transcription et la traduction.
Voici un résumé de ces deux processus.
Dans le noyau de la cellule (transcription)
-
L’ADN est comme un grand livre de recettes. Il contient toutes les informations pour synthétiser les protéines nécessaires au corps humain. Ceci dit, si on souhaite synthétiser une seule protéine, on a besoin d’une seule recette.
-
Une enzyme lit l’ADN et copie l’unique recette nécessaire. La copie de cette recette se trouve sous la forme d’une molécule : l’ARN messager (ARNm).
Hors du noyau de la cellule (traduction)
-
L’ARNm quitte le noyau pour aller dans le cytoplasme où aura lieu la synthèse de la protéine.
-
Le ribosome joue le rôle de cuisinier. Il lit l’ARNm comme une recette et utilise les acides aminés comme ingrédients nécessaires à la fabrication de la protéine souhaitée.
-
Une fois que la synthèse de la protéine est terminée, elle est libérée dans le cytoplasme de la cellule.
La transcription est la première étape de la synthèse des protéines. Elle consiste à copier l’information génétique comprise sur un segment d’ADN en produisant une molécule d’ARN messager.
L’ADN comprend l’information nécessaire à la synthèse de l’ensemble des protéines du corps. Ainsi, l’ADN est une molécule longue et volumineuse, ce qui fait qu’elle ne peut pas quitter le noyau de la cellule pour participer directement à la synthèse d’une protéine. Il faut donc produire une molécule plus petite qui peut quitter le noyau et transporter l’information génétique nécessaire : il s’agit de l’acide ribonucléique messager, ou ARNm.
L’ADN et l’ARN sont des molécules qui comportent plusieurs points communs. Par exemple, elles sont toutes deux formées d’un assemblage de sucres, de bases azotées et de groupements phosphatés. Ces molécules ont aussi des différences qui sont résumées dans le tableau suivant.
| ADN | ARN | |
|---|---|---|
| Nom complet | Acide désoxyribonucléique | Acide ribonucléique |
| Type de sucre | Désoxyribose | Ribose |
| Types de bases azotées | Adénine Thymine Guanine Cytosine |
Adénine Uracile Guanine Cytosine |
| Nombre de brins | Généralement deux brins | Généralement un brin |
La transcription de l’ADN en ARNm s’effectue selon les étapes suivantes.
Initialement, on voit que l’ADN est constitué de deux brins comprenant des bases azotées complémentaires (couple A-T, et couple G-C). On retrouve également des bases azotées libres dispersées dans le noyau.
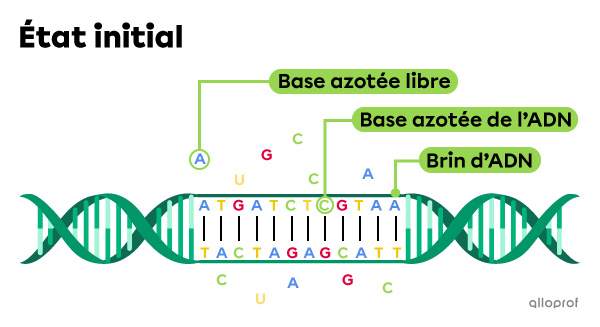
Lors de la première étape de la transcription, une enzyme sépare les deux brins d’ADN. De plus, en utilisant les bases azotées libres dans le noyau, l’enzyme associe chaque base azotée du brin d’ADN à une base azotée complémentaire. Ainsi, un brin d’ARNm est formé.

Dans la deuxième et dernière étape, le brin d’ARNm est complété. Il se dissocie du brin d’ADN et peut, au besoin, subir quelques dernières modifications. Il peut alors voyager à l’extérieur du noyau, dans le cytoplasme de la cellule.

L’ARNm est donc une molécule complémentaire à l’ADN. Lors de la formation de l’ARNm, les bases azotées s’associent de la même manière qu’elles le font entre deux brins d’ADN. Toutefois, lors de la synthèse de l’ARNm, la thymine (T) est substituée par l’uracile (U). Le tableau suivant compare l’appariement des bases azotées dans deux brins d’ADN et lors de la formation de l’ARNm.
| Appariement des bases azotées dans deux brins d'ADN (Brin d'ADN-Brin d'ADN) |
Appariement des bases azotées lors de la formation de l’ARNm (Brin d’ADN-Brin d’ARNm) |
|---|---|
| Guanine-Cytosine Cytosine-Guanine Thymine-Adénine Adénine-Thymine |
Guanine-Cytosine Cytosine-Guanine Thymine-Adénine Adénine-Uracile |
Voici un brin d'ADN.
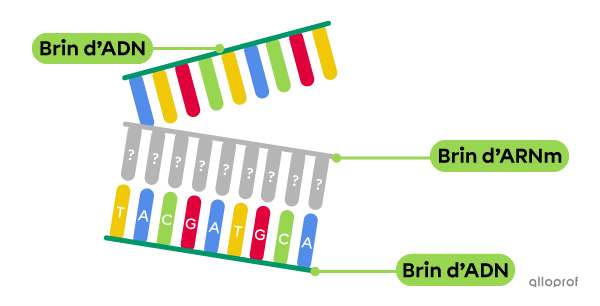
Quelle est la séquence d’ARNm correspondant à ce brin d’ADN?
Le brin d’ADN qui guide la formation de l’ARNm possède la séquence suivante : TACGATGCA.
En se référant au tableau précédent, on peut affirmer que :
-
la thymine (T) de l’ADN se couplera à l’adénine (A) de l’ARNm;
-
l’adénine (A) de l’ADN se couplera à l’uracile (U) de l’ARNm;
-
la cytosine (C) de l’ADN se couplera à la guanine (G) de l’ARNm;
-
la guanine (G) de l’ADN se couplera à la cytosine (C) de l’ARNm.
On obtient alors ce brin d’ARNm.

La séquence du brin d’ARNm est donc AUGCUACGU.
Maintenant que l’étape de transcription est complétée, la cellule peut procéder à la traduction de l’ARN messager (ARNm) en protéine.
-
La traduction est la deuxième étape de la synthèse des protéines. Elle correspond à la lecture de l’ARNm et à la synthèse de la protéine par les ribosomes de la cellule.
-
L’ARN de transfert (ARNt) est un type d’ARN qui se lie à l’ARNm. Il transporte les acides aminés qui formeront la protéine.
-
Les ribosomes sont des organites qui se trouvent au sein de la cellule à la surface du réticulum endoplasmique.
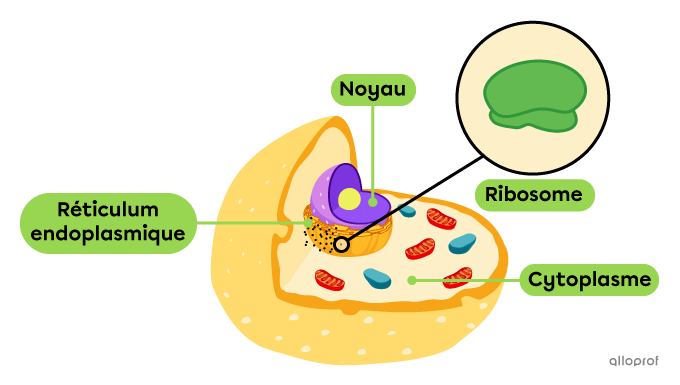
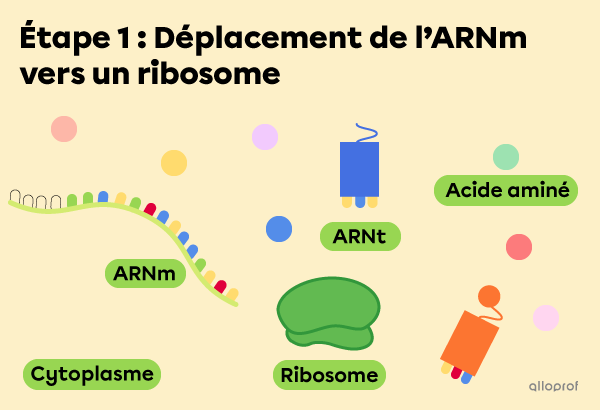
Lorsque l’ARNm quitte le noyau pour rejoindre le cytoplasme, il s’approche d’un ribosome. Lors de cette première étape, plusieurs particules flottent déjà dans le cytoplasme, dont l’ARN de transfert (ARNt) et des acides aminés.
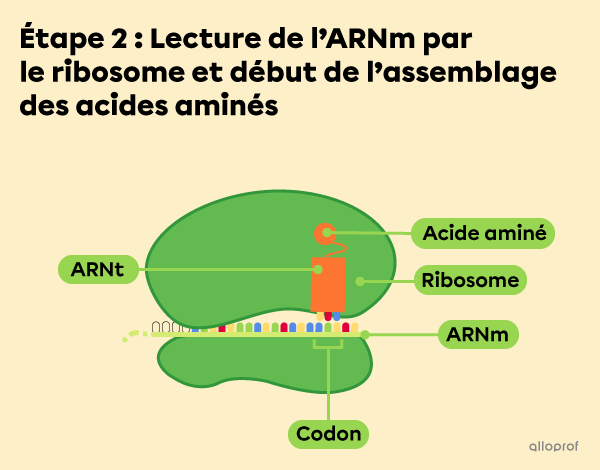
Dans l’étape 2, l’ARNm se fixe au ribosome. Le ribosome commence alors à lire l’ARNm par groupe de trois bases azotées. Chaque triplet de bases azotées est ce qu’on appelle un codon.
La lecture d’un codon d’ARNm par le ribosome provoque l’arrivée d’un ARNt correspondant. L’ARNt agit comme une navette. Son rôle est de transporter un acide aminé spécifique qui fera partie de la future protéine.
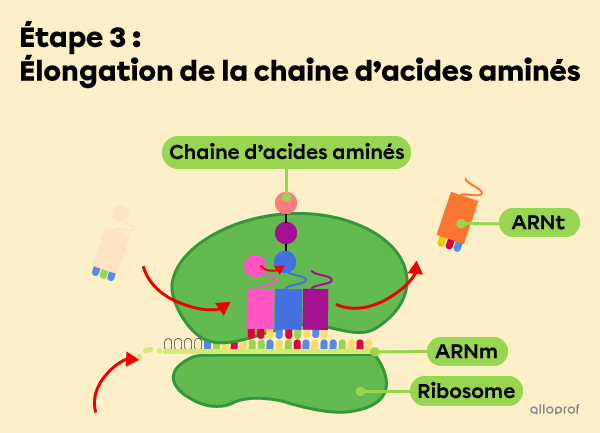
Au fur et à mesure que l’étape précédente se répète, les acides aminés se lient et créent une chaine qui s’allonge.
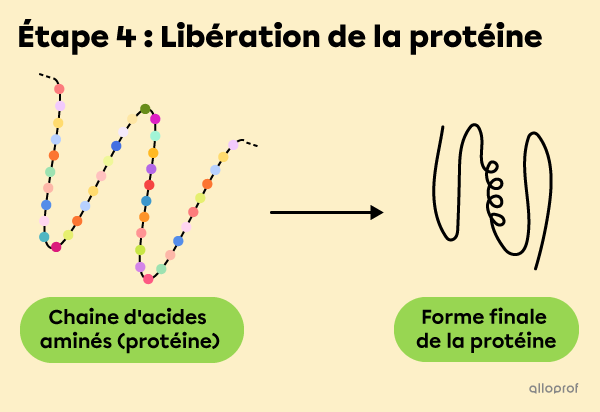
À l’étape 4, lorsque la synthèse est terminée, la chaine d’acides aminés est libérée dans le cytoplasme. Elle s’enroule et devient une protéine avec sa forme tridimensionnelle finale.
Un codon d’ARNm correspond à un acide aminé spécifique. Par exemple, la lecture d’un codon d’ARNm comportant un triplet de bases azotées U, U et C permet à la future protéine de comporter un acide aminé appelé phénylalanine. Autrement dit, un codon UUC code pour de la phénylalanine.
Le tableau de référence suivant permet de déterminer les codons responsables de l’ajout d’un acide aminé spécifique.
| 1re base azotée | 2e base azotée | 3e base azotée | |||||||
| U | C | A | G | ||||||
| U | UUU | Phénylalanine | UCU | Sérine | UAU | Tyrosine | UGU | Cystéine | U |
| UUC | UCC | UAC | UGC | C | |||||
| UUA | Leucine | UCA | UAA | - | UGA | - | A | ||
| UUG | UCG | UAG | UGG | Tryptophane | G | ||||
| C | CUU | CCU | Proline | CAU | Histidine | CGU | Arginine | U | |
| CUC | CCC | CAC | CGC | C | |||||
| CUA | CCA | CAA | Glutamine | CGA | A | ||||
| CUG | CCG | CAG | CGG | G | |||||
| A | AUU | Isoleucine | ACU | Thréonine | AAU | Asparagine | AGU | Sérine | U |
| AUC | ACC | AAC | AGC | C | |||||
| AUA | ACA | AAA | Lysine | AGA | Arginine | A | |||
| AUG | Méthionine | ACG | AAG | AGG | G | ||||
| G | GUU | Valine | GCU | Alanine | GAU | Acide aspartique | GGU | Glycine | U |
| GUC | GCC | GAC | GGC | C | |||||
| GUA | GCA | GAA | Acide glutamique | GGA | A | ||||
| GUG | GCG | GAG | GGG | G | |||||
*Le triplet AUG code pour la méthionine, mais est aussi un codon d'initiation, signalant le début de la séquence de codons.
**Les triplets UAA, UAG et UGA ne codent pas pour des acides aminés mais ils sont des codons de fin de traduction, signalant la fin de la séquence de codons.
Ainsi, afin de produire la séquence d’acides aminés suivante (soit tyrosine-phénylalanine-histidine-histidine-cystéine-phénylalanine-tyrosine-leucine), on peut anticiper qu’un brin d’ARNm pourrait comprendre les codons UAU-UUC-CAU-UGU-UUC-UAC-CUG.